
写一些笔记记录一下领域的最新进展。会持续更新,主页的 blog 发表日期仅供参考~
1. 正向渲染加速
Gaussian Point Splatting [1] [Project]
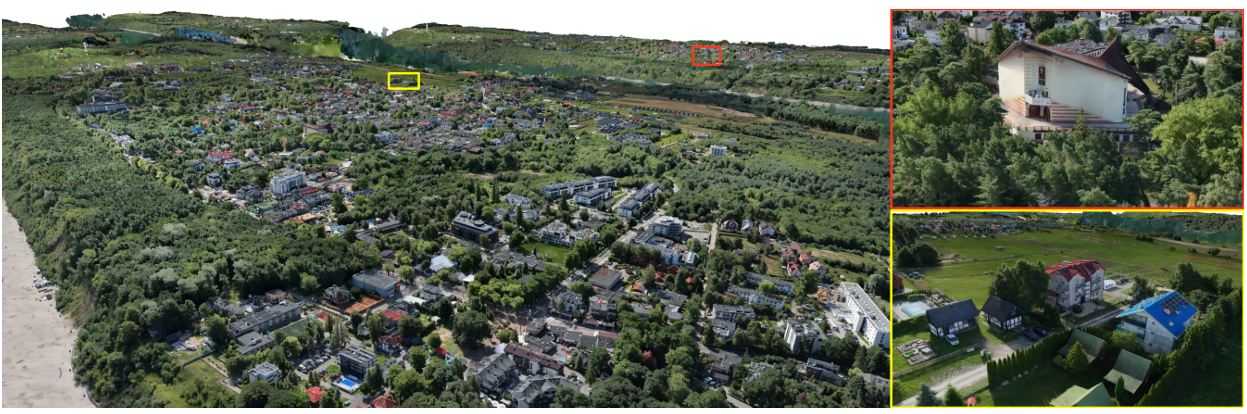
本文用蒙特卡洛方法代替深度排序,加速了超大 3DGS 场景在 GPU 上的正向渲染过程。目前仅支持正向渲染。
本文注意到单个 Gaussian Splat 到屏幕空间的行为可以等价于在屏幕空间上按一个 Gaussian 分布放回采样 个点的结果的期望( 和 Gaussian 的参数相关)。而一系列 Gaussians 做 Alpha Blending 的行为可以等价于,对每个 Gaussian 采样 个点,然后对每个像素取深度上最靠前的点 作为 Splat 结果的无偏估计值。
一方面该方法优化掉了每个 Tile 都要 GPU 排序的瓶颈,优化到了关于 Gaussian 数量的线性复杂度,还可以通过遮挡剔除等方式进一步剪枝。另一方面这个过程还可以高度并行化,取 的操作也只需要在屏幕空间缓冲区做一个很高效的原子查询+覆盖,因此跑起来就很快。并且对于超大场景,由于存在大量小于 1 像素的极小 Gaussians,这些 Gaussians 在传统管线中会占用大量的排序计算,造成性能瓶颈,而在该管线中可能只对应非常小的采样点数,因此效率提升会更大。
由于其将深度排序行为替换成了蒙特卡洛方法,它还天然支持渲染出 3DGRT 特有的 “Gaussian 穿插”行为,避免了相机移动时的 Popping 现象。这种 Splatting 方法似乎是可以做到和 3DGRT 管线一致的。(3DGRT 管线可能被迫在射线相交的高斯球过多时放弃靠后的高斯球,但这一方面影响不大,另一方面也可以用随机终止 [2] 代替 Alpha Blending 做到一致无偏)

论文提到可微渲染的困难主要有: 是整数,关于 Gaussian 的位姿和密度不可微; 操作不可微;可微难以做到 空间复杂度。
这篇的效率瓶颈主要在原子操作互斥锁、采样 Gaussians 时的显存吞吐、分布本身缺陷造成大 Gaussians 生成过多采样点拖慢效率等。对于这些问题本文都用了一些策略去应对。对于采样过程论文提到计算 CDF 并二分的方法比用别名法要快,每次相机移动都会改变所有 Gaussian 的 分布的确是个麻烦事。
感觉这篇 Monte Carlo 方法的主要缺陷是,对屏幕空间颜色贡献较大的 Gaussian Point 主要是靠近相机的 Gaussian Point,被挡住的 Gaussian Point 实际上的贡献密度很小。感觉缺一点重要性采样,也许可做哇。这个问题在传统 3DGS 管线中也存在。本文的方法主要是靠遮挡剔除解决这个问题的。
本文和 Stochastic Ray Tracing for the Reconstruction of 3D Gaussian Splatting [2] 同属于用 Monte Carlo 概率方法优化 3D Gaussian Primitive 渲染的方法。区别在于后一篇是基于 3DGRT 管线直接用 Monte Carlo 方法代替了 排序 + Alpha Blending 的过程,保持可微,效率瓶颈仍在求交;而该论文提出了一种比较新的 Splatting 方式,不需要求交、排序等操作,但仅支持正向渲染。二者每 spp 的像素颜色分布也有所不同。这篇的思路中被挡住的 Gaussians 基本就不会被采样到,从而不会影响效率。
在 NeRF 上的类似工作则在 2023 年就有人做过 [3],大致思路就是考虑到密度估计比颜色估计更快(只用查哈希表),因此先求路径上颜色贡献关于路径的 CDF,然后按该累计分布密度随机采样几个点得到无偏估计,最后做图像空间降噪。这篇的效率提升是传统方法的 7 倍,要低于 Gaussian Point Splatting 的提升倍数,可能深度排序在 3DGS 中还是太耗了。这篇在当年是 Conference Paper。不知道这样改进后密度估计的开销占比有多大。如果要设计基于和 Gaussian Point Splatting 一样的采样-覆写的方法,主要困难是对视锥内的密度场采样。不知道能不能靠预计算做一下。这篇由于是用贡献 CDF 采样颜色,所以天然不易采样到被挡住的点,比较类似 Stochastic 3DGRT。
由于这篇和 Stochastic 3DGRT 一起将随机深度采样的方法变成了最高效的 3D Gaussian Primitives 正向渲染方法,基于低 spp 渲染结果先验的降噪工作可能会变得更加重要。
这个项目没有什么依赖,工程非常好编译,感觉对进一步优化很友好。在我的 4060 笔记本电脑上试着跑了一下, 30M Gaussians 的场景可以跑到实时,但是帧间的噪声还是很明显。感觉网络降噪需求很迫切哇,想想每个像素能不能拿到更多信息,比如其对应的 Gaussian 的元信息,然后在相邻像素之间做一点概率统计重用什么的,感觉很有搞头啊。

Mobile3DGS³: Accelerate Mobile 3DGS Rendering via Gradient-Aware Super-Sampling and Frame Interpolation
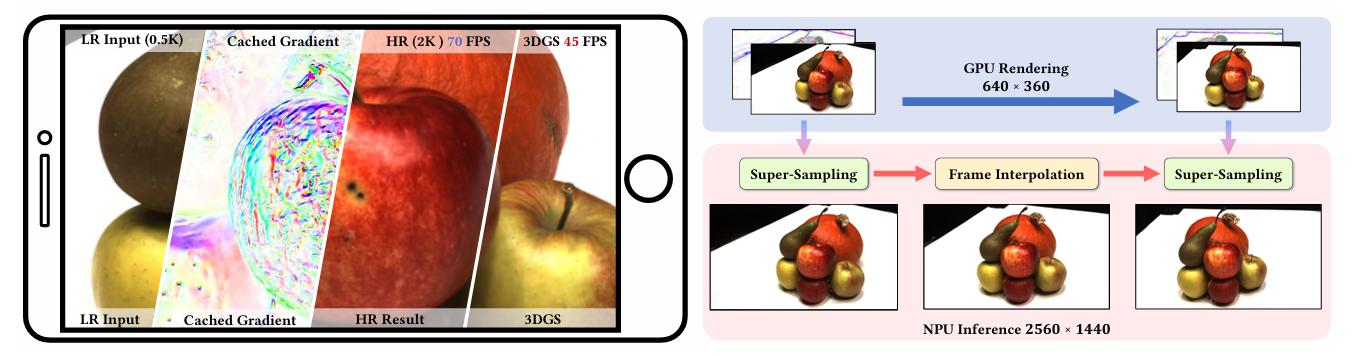
曾经助教、现好朋友 @SyouSanGin 的第一篇 SIGGRAPH,靠内部关系拿到了文章。
本文做的是 3DGS 的超分。
主要是观察到 3DGS 的屏幕空间梯度可以提前计算并缓存,在 0.25x 分辨率渲染时 Splat 颜色的同时也 Splat 每个像素的梯度信息,进一步做像素间多项式样条插值,即可在更快的速度内得到高质量的正向渲染结果。
由于 3DGS 在图像空间的渲染结果本来就是比较光滑的(受到 3DGS 基元大小的限制,还受到训练集分辨率的限制),因此样条插值效果就很好。
据原作者所说,后期的神经网络图像调优和帧间插值在本文的方法中贡献并不大。作者也测试过用二阶微分信息进一步优化插值的信息量,但并没有明显提升。
过去的渲染超分方法(不限于 GS)普遍需要 GBuffer 作为网络的补充信息,而本文面对 3DGS 的任务当然是没有 GBuffer 的,合理利用已有信息量(像素点的微分信息)对邻域进行插值是相当漂亮的思路。在 25 年 11 月该文作者发现有一篇 ArXiv 论文 [4] 和他的思路撞了。但这篇提出了切空间梯度缓存的方法并且在工程上实现在了 GPU+NPU 上,在效率上做到了 make sense。
很喜欢这种充分挖掘并高效利用信息量,而不是靠神经网络去暴力发现信息的规律的工作。
2. 表达能力优化
Ref-DGS: Reflective Dual Gaussian Splatting [5] [Project]

靠构建“虚像”实现 2DGS 近场镜面反射的工作。靠神经网络去暴力发现信息的规律的工作
过去的工作在重建镜面/Specular 场景时经常存在强行拟合镜面反射导致几何塌陷的问题,在几何出问题的同时光照也没能很好地拟合。因此本文希望解耦仅与几何相关的视角无关光照和 Specular 光照,从而在可微渲染过程中同时得到可信的几何和可信的 Specular 光照。
考虑将光照分为视角无关和视角相关两部分相加,视角无关的部分可以很好地由传统的、几何紧贴表面的 2DGS(Geo-GS)表示。因为有了可信的几何所以也可以在上面得到 Normal 并优化 Diffuse 和 Roughness 材质参数。注意这里的 Diffuse 是加性的光照“直流分量”,而不是乘性的 Albedo,在定义上和材质模型有一些区别。
视角相关部分进一步分为相机位姿无关(远场)和相机位姿相关(近场)部分,前者可以用可学习的环境贴图表示,后者则是本文主要的创新点,用另一组存储特征向量的 2DGS(Local-GS)表示,表示镜面内部的“虚像”。将 Local-GS Splat 到屏幕上、对每个像素将 Roughness 信息、相机与法线夹角信息和环境光贴图一起送进一个轻量的可学习 MLP 得到 Specular,直接加到 Diffuse 图上。
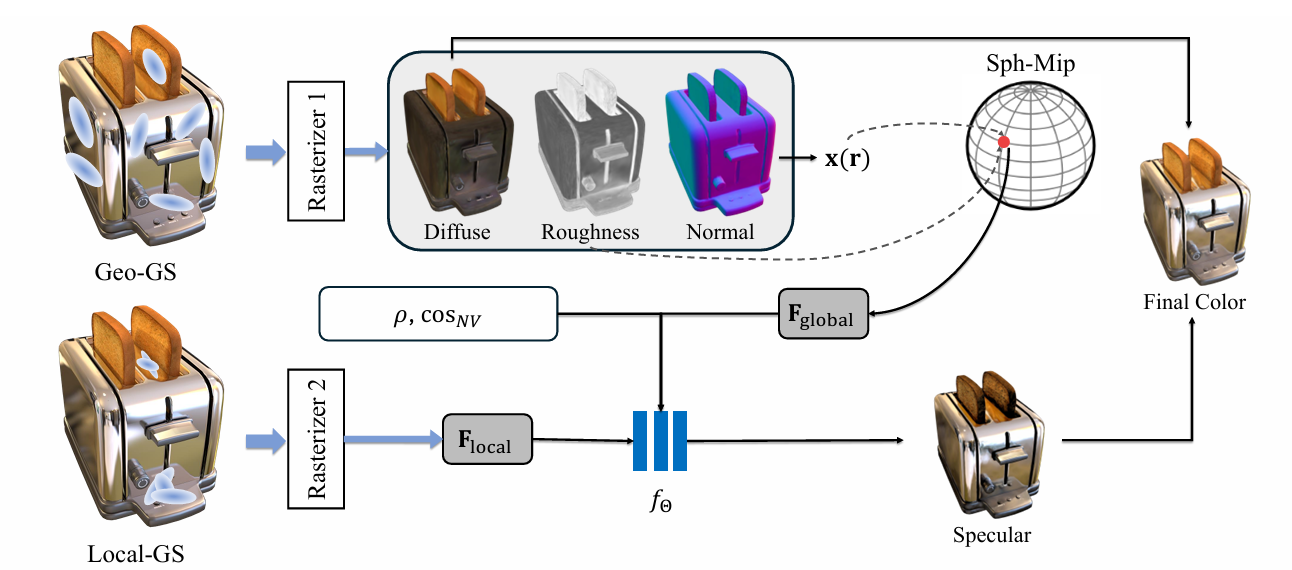
Geo-GS 的训练是有深度先验做引导的。在合适的超参数下,Geo-GS 会忠实地贴在几何表面,Local-GS 则会进入物体内部拟合 Specular,从而得到优秀的几何。同时论文也确实能很好地表现将 Diffuse 部分和 Specular 部分解耦开(虽然这不是我们想要的解耦“烘焙式光照”)。
很难信任用“虚像”的方法来做 Specular 的视差现象。在有曲率的曲面内部仍然做透视投影感觉根本说不通,不知道神经网络学到什么东西就拟合出来了。很难想象物体内部多个视角生成的 Local-GS 和轻量 MLP 是怎么耦合的。MLP 训练的参数是针对全局的,不知道为什么不做预训练。这个方法看起来也做不了薄物体,不知道怎样才能避免干扰。对 3DGS 不擅长处理的视角相关光照分开处理当然是合理的,但这样做实在让人不安。实验展示了指标上升,但看不出指标上升是因为渲染管线好了还是单纯因为几何好了(考虑到这里几何还用了先验)。
但有启发性的一点是,把特征放在物体内部确实是合乎 Specular 信息的规律的:当绕着金属物体旋转时,高曲率边界的光照会高频快速地改变,这一部分较大的信息量可以由贴近边界的小高斯去拟合得到;内部的光照会相对较慢地流动,这一部分视角间共用的信息可以由靠近物体内部的大特征高斯拟合。总觉得反射信息共用应当有更好的方式去做。
Learning View-Dependent Splatting Kernels [6] [Project] [GAMES]

尝试通过学习 Splatting Kernel 提高表达能力。看实验感觉主要优化的是输入视角不充分的区域。 靠神经网络去暴力发现信息的规律的工作之二
本文的渲染管线是先将 Gaussian 椭球作为代理几何 Splat 到屏幕空间以得到 Splat 区域每个点到重心的标准化距离;而得到颜色的方法是对每个 Gaussian 将 Gaussian 存储的隐向量(通常为 5 维)、相机空间变换(坐标、缩放因子、旋转矩阵)送进一个全局的“神经投影”MLP 中“投影”得到一个 2D 空间的隐向量,再对每个像素点用另一个全局“解码器” MLP 接受每个 Gaussian 的隐向量以及标准化距离、输出该 Gaussian 对该像素的贡献,最后做 Alpha Blending 得到最终颜色。训练过程中,Gaussian 的隐向量和相机空间变换都是可学习的参数。
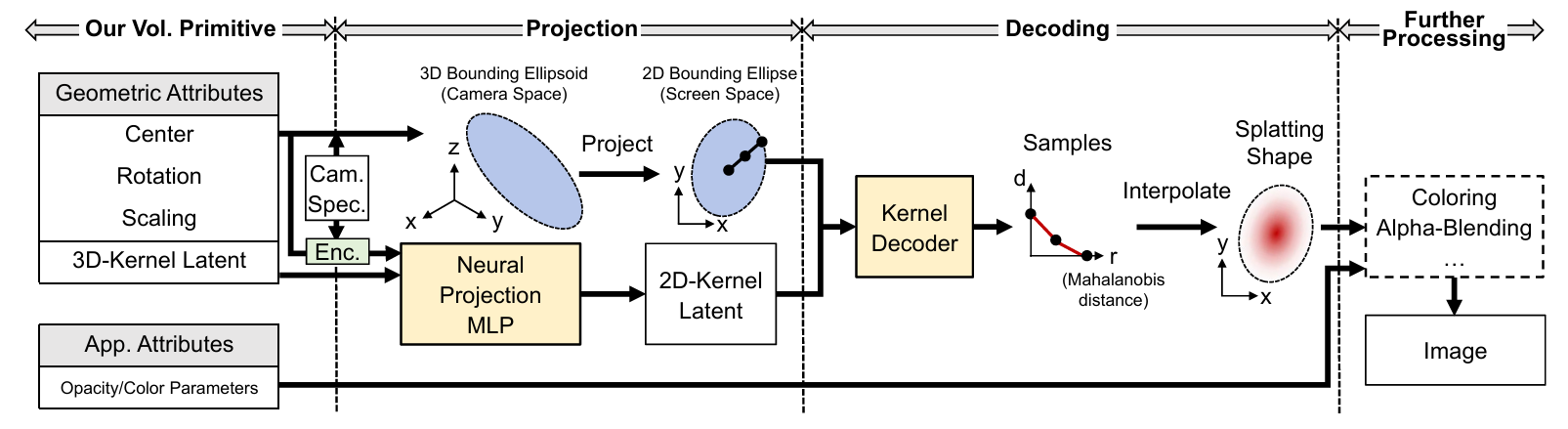
投影过程换成了“神经投影”,输出值自然可以根据视角不同发生变化,比原先用球谐函数的表达能力要强很多。正向渲染过程中由于 的推理开销较大,因此直接对每个 Gaussian 预计算标准化后径向每个采样点的颜色值并线性插值。
一个有趣的现象是,学习到的 Kernel 参数在相似的场景、物体下会有相似的分布,如可以为树叶、头发等材质生成相似的“最适合”的 Kernel 形状,说明 Kernel 确实学到了一些物体本身的光照特征。
作者提到这篇解决的问题是让 3DGS 的视角一致性更好了,如一个“长条形”的高斯从短边积分和从长边积分的密度应该不同,一篇 EG2025 的文章《Does 3D Gaussian Splatting Need Accurate Volumetric Rendering?》[7] 也论述了这种视角依赖性的现象,虽然没太看懂,感觉怪怪的。
我觉得这篇之所以效果比较好是因为它把高斯的不同视角变得独立了,如优化正面能只优化正面,而不会在侧面产生一些伪影(所以输入不充分的区域效果好)。同时它的神经 Kernel 也保证了比较光滑,不会优化出一些比较明显的伪影(和 GabSplat 相比)。总之感觉更多是降低了“出错”的概率,而不是去让好的地方更好了。比较期待能用一个足够好的 Kernel 把细节变得更漂亮,消掉那种“3DGS 痕迹”。实验上的提升比起传统的 3DGS 在 2dB PSNR 左右,和 SOTA 方法相比基本上不到 1dB。
3. 辐射场的新应用
Radiance Fields from Photons [8] [ArXiv]

针对“单光子相机”提出的 NeRF 辐射场训练方法。
“单光子相机”(Single Photon Camera)指每个像素仅有 和 状态表示是否有光子,但帧率极高,可以理解为曝光时间极短、曝光次数极多的相机。“传统相机”(Conventional Camera)则指像素值在 之间、帧率正常、曝光时间长的相机。可以用前者的图像通过累计多次曝光得到后者的图像。前者能提供更多的信息量,特别地,可以避免长时间曝光产生的过曝、拖影等瑕疵,也能解决低亮度下传统相机信息量不足导致重建效果差的问题。现在越来越多的设备开始支持这种单光子相机,因此该论文提出的方法具有很大的实际应用价值。
单光子相机的输入数量极大、每张输入的噪声也很高,且由于高噪无法通过几张相邻输入的关系得到相机位姿。本论文针对这种输入解决了三个问题:
辐射场训练:根据泊松分布,一个像素被打进一个光子的概率 和像素内辐射强度 、曝光时间 的关系为
单光子相机得到的结果服从以上概率的二项分布,训练一个可做体积分的概率场而非辐射场,由最大似然估计的原理知优化 即可,形式上和传统 NeRF 是相同的,只是积分后从概率转换到辐射强度需要经过一个含曝光时间 参数的映射。
- 相机位姿:先根据相邻帧模拟曝光一次重建一个相对不可靠的“虚拟”位姿,然后在辐射场训练的同时把相机位姿也作为可训练参数进行优化。考虑到曝光极频繁的相机运动一定是非常光滑的,本文用低通滤波后的位姿和当前位姿的 Loss 作为一个正则项引导位姿的平滑优化。
- 大输入量:bit 压缩、实时磁盘读取等 common trick。
本文 claim 的针对运动相机、低光照场景、过曝场景的优化是显然的,因为单光子相机提供了足够多的信息量。技术上感觉也没什么难想到的地方,感觉像是纯粹应用比较小众且有前景就上了。这篇论文的 writing 也很神奇,每一段都有小标题,大标题的用词也很不同寻常,第一次见这种风格的文章。
本文第 7 节论述了对迁移到 3DGS 的尝试,作者认为 3DGS 对输入的噪声过于敏感,以至于在该应用时优化会非常不稳定,造成大量的过拟合噪声,剪枝策略甚至会因为场景中大部分像素的方差都过大而把高斯球删光。论文提出先在预曝光的结果上训练一段时间再逐渐减小曝光时间精细调整(Sheduled Temporal Smoothing 策略)可以得到不错的结果,但可以观察到这仍然引入了运动模糊的问题。这也是一个未来改进方向(抗输入噪声的 3DGS)。

到底是从哪里知道这种新应用的哇,我也想找一点冷门的应用场景写论文……不知道这篇的应用能不能继续往后水几篇。
4. 这段时间读到的一些非 SIG26 文章补充
MVInverse: Feed-forward Multiview Inverse Rendering in Seconds [9] [Project] (CVPR2026)
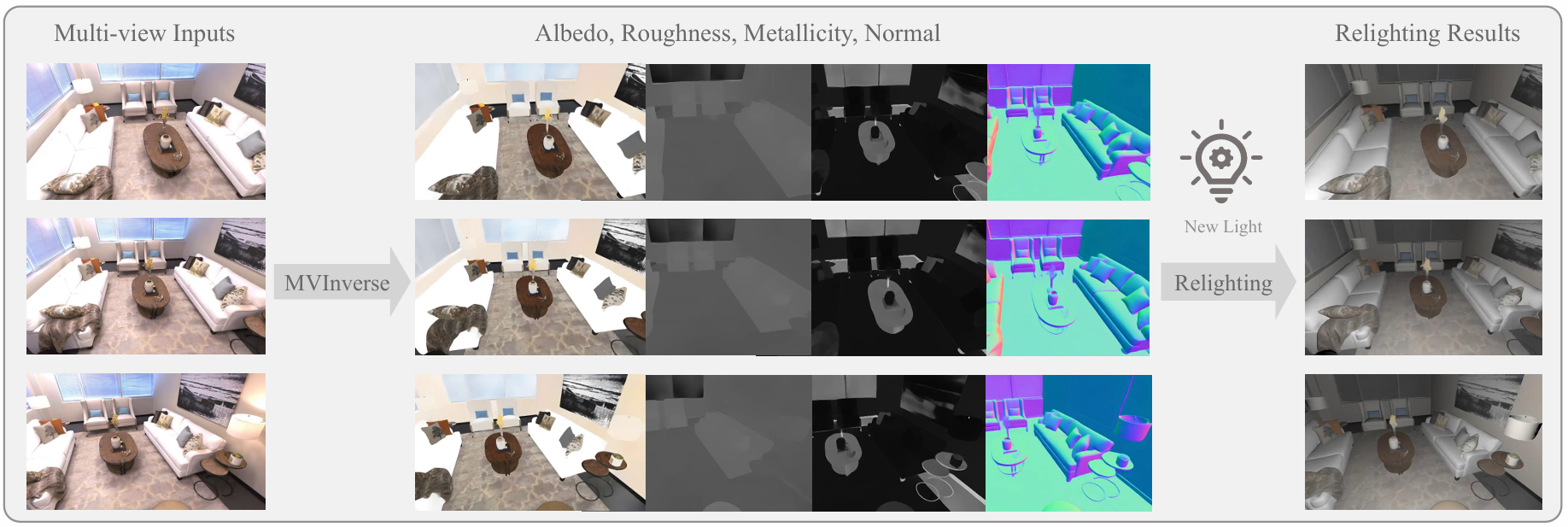
输入多视角图片,输出多视角 G-Buffer,效率优化到实时级别。
本文提出了交替注意力网络结构,在以往单图注意力网络的基础上交替叠加全局、多图之间的注意力网络,从而能在不同视角的注意力之间“对账”保证多视角一致性。
对于编码器,在使用 DINOv2 提供语义先验的基础上还用了 ResNeXt 编码器提取高频特征,保证输出图片是锐利的。
训练阶段采用两阶段训练,第一阶段在标注正确的 3D 数据集上学习物理规律,第二阶段自监督、用真实视频的光流约束,保证两帧之间对同一点的预测输出一致,以提高训练数据量。用锚点损失防止模型微调时产生漂移。
因为以往的预测都是单图的,这里多图提供了更大的信息量,因此指标提升是可以预见的。并且因为多图逆渲染的需求是存在的(可微渲染这边基本都在做这种),故事也说得通。
我没有怎么看过生成方面的文章,每学一个新东西都觉得好神奇。总感觉材质重建这种任务还是得靠生成式方法。
HDR-NeRF: High Dynamic Range Neural Radiance Fields [10] Project (CVPR 2022)

用多个曝光条件不同的图片训练 HDR 的 NeRF 场。
在体积分得到辐射量的后端再接一个根据相机曝光原理设计的可学习含参函数,就能顺便把该视角图片的曝光曲线也学了,因为信息量充分,所以能学到准确的 HDR NeRF 场。
更早的一篇类似的 NeRF in the Wild [11] 也能达到类似训练 HDR 场的目的,但这一篇主要的卖点是在拍摄条件较差的输入下重建可信的 NeRF 场。
因为当时想着材质重建做不好可能是光场 LDR 的原因,就看了这篇,结果做了实验发现 HDR 的光场并不能得到什么提升,遂放弃。这篇感觉也是一篇从应用切入的文章,好羡慕这种发现小众应用场景的科研能力。
References
- [1] J. Rijsdijk, C. Peters, M. Weinnman, and R. Marroquim, “Gaussian Point Splatting,” ACM Trans. Graph., vol. 45, no. 4, 2026, doi: 10.1145/3811272.
- [2] P. Xu, X. Sun, K. Mullia, R. Fei, I. Georgiev, and S. Zhao, “Stochastic Ray Tracing for the Reconstruction of 3D Gaussian Splatting.” [Online]. Available: https://arxiv.org/abs/2603.23637
- [3] K. Gupta et al., “MCNeRF: Monte Carlo Rendering and Denoising for Real-Time NeRFs,” in SIGGRAPH Asia 2023 Conference Papers, in SA '23. Sydney, NSW, Australia: Association for Computing Machinery, 2023. doi: 10.1145/3610548.3618221.
- [4] S. Niedermayr and C. N. R. Westermann, “Lightweight Gradient-Aware Upscaling of 3D Gaussian Splatting Images.” [Online]. Available: https://arxiv.org/abs/2503.14171
- [5] N. Fan, Y. Wang, D. Yan, and P. Wonka, “Ref-DGS: Reflective Dual Gaussian Splatting.” [Online]. Available: https://arxiv.org/abs/2603.07664
- [6] H. Ding, Z. Liu, F. Pei, K. Zhou, and H. Wu, “Learning View-Dependent Splatting Kernels.” [Online]. Available: https://arxiv.org/abs/2605.25426
- [7] A. Celarek, G. Kopanas, G. Drettakis, M. Wimmer, and B. Kerbl, “Does 3D Gaussian Splatting Need Accurate Volumetric Rendering?,” Computer Graphics Forum, vol. 44, no. 2, p. e70032, 2025, doi: https://doi.org/10.1111/cgf.70032.
- [8] S. Jungerman, A. Garg, and M. Gupta, “Radiance Fields from Photons.” [Online]. Available: https://arxiv.org/abs/2407.09386
- [9] X. Wu, C. Ren, J. Zhou, X. Li, and Y. Liu, “MVInverse: Feed-forward Multi-view Inverse Rendering in Seconds.” [Online]. Available: https://arxiv.org/abs/2512.21003
- [10] X. Huang, Q. Zhang, Y. Feng, H. Li, X. Wang, and Q. Wang, “Hdr-nerf: High dynamic range neural radiance fields,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18398–18408.
- [11] R. Martin-Brualla, N. Radwan, M. S. M. Sajjadi, J. T. Barron, A. Dosovitskiy, and D. Duckworth, “NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections.” [Online]. Available: https://arxiv.org/abs/2008.02268